21 / 09 / 17
'👩👩👧👧'.length === 11 ? Emoji 有多长
事情的起因是这样的,前端给服务端(Golang)一段文本,服务端将文本中的链接进行解析,然后将解析的结果返回给前端。
"test:https://google.com" { offset: 5, length: 18, title: "Google", url: "https://google.com" }
这看起来似乎没有问题,前端通过 String.length 方法,通过服务端数据,将文本渲染成对应的 URL 预览形态。
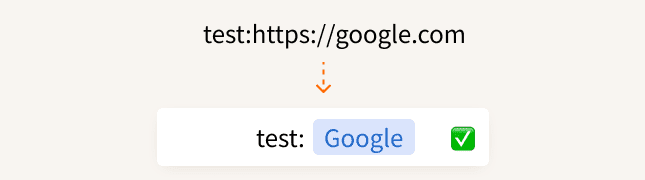
但是当我测试了另外一个文本时,发现了问题:
"😉https://google.com" { offset: 4, length: 18, title: "Google", url: "https://google.com" }
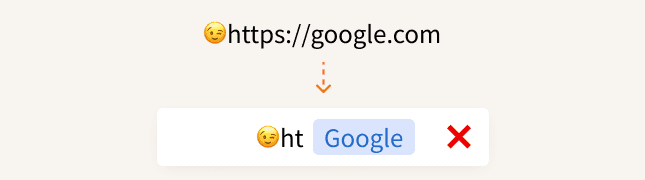
字符串的 offset 计算出现了不一致,服务端计算 "😉"的长度为 4,而前端计算的长度为 2,为什么会发生这种情况呢?
经过和服务端了解,他们计算字符串长度使用的是 Golang 里面的 len 方法,而 Go 中的字符串默认是 UTF-8 编码的,所以计算 len("😉") 的长度为 4;JavaScript 内部把字符串存储为 UTF-16,而 JavaScript 的 String.length 方法返回字符串中字符编码单元(或者叫做代码点)的数量,计算 长度为 2。
那么一个 Emoji 究竟有多长呢?
'⛱'.length === 1,'😉'.length === 2,'👩👩👧👧'.length === 11 视觉看到的并不是真相。
事实上,Emoji 是 Unicode 字符集的一部分。事物的组成方式:字节组合成字符编码单元(或者叫做代码点,unicode number),而字符编码单元组合成字形(视觉符号,visual symbols)。在 UTF-16 中,Emoji 的长度可能是 1 或 2 甚至更多。
'⛱' = '\u26f1'
'😉' = '\ud83d\ude09'
'👩👩👧👧' = '\ud83d\udc69\u200d\ud83d\udc69\u200d\ud83d\udc67\u200d\ud83d\udc67' (哇,爆炸...)
Emoji 表情有可能是多个 Emoji + 一些额外的字符 来拼接出来的,像 '👩👩👧👧' 就是由 ['👩', '', '👩', '', '👧', '', '👧'] 拼接而成的,单个 Emoji 长度为 2,中间的连接字符长度为 1,故返回了 11。
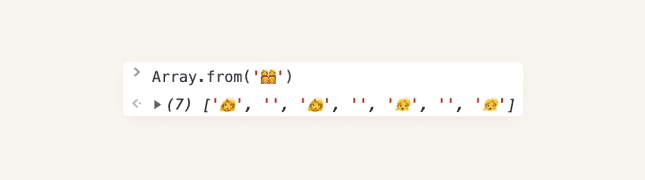
如何获取 '👩👩👧👧' 的长度为视觉的 1 呢,可以使用 lodash 的 toArray 方法,_.toArray('👩👩👧👧').length = 1,其内部实现 了对 unicode 字符转换数组的兼容。
关于遇到的这个业务场景,前后端以及多端(iOS、Android)问题解决方案:统一使用 utf-8 来计算。
/** * 将普通的字符串(utf16)转换为 utf8 编码,主要应用于字符串包含 emoji 场景的长度计算和服务端统一 * @param string 普通的字符串(utf16) * @returns utf8 编码的字符串 */ export const encodeUtf8 = (string: string) => unescape(encodeURIComponent(string)); /** * 将 utf8 编码的字符串转换为普通的字符串(utf16),主要应用于字符串包含 emoji 场景的长度计算和服务端统一 * @param string utf8 编码的字符串 * @returns 普通的字符串(utf16) */ export const decodeUtf8 = (string: string) => decodeURIComponent(escape(string));
当然可能更好的办法是由服务端返回解析后的完整的数据结构。
后记
- 这里有一篇经典且可以时常翻阅的关于 Unicode 和字符集的文章:The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) 。
- 当出现前后端都计算字符串长度,甚至涉及到数据库存储时,要警惕“编码陷阱”。
- Hack News 上关于 Emoji.length == 2 的讨论。
“如果你想有任何想法,欢迎在 X/Twitter 上联系我。”